自然语言处理综述
1. 引言
自然语言是指人类日常使用的语言,比如:中文、英语、日语等。自然语言灵活多变,是人类社会的重要组成部分,但它却不能被计算机很好地理解。为了实现用自然语言在人与计算机之间进行沟通,自然语言处理诞生了。自然语言处理(Natural Language Processing, NLP)是一个融合了语言学、计算机科学、数学等学科的领域,它不仅研究语言学,更研究如何让计算机处理这些语言。它主要分为两大方向:自然语言理解(Natural language Understanding, NLU)和自然语言生成(Natural language Generation, NLG),前者是听读,后者是说写。
本文将从自然语言处理的历史与发展讲起,进而分析目前深度学习在自然语言处理领域的研究进展,最后讨论自然语言处理的未来发展方向。
2. 历史与发展
1950年,计算机科学之父图灵提出了“图灵测试”,标志着人工智能领域的开端。而此时,正值苏美冷战,美国政府为了更方便地破译苏联相关文件,大力投入机器翻译的研究,自然语言处理从此兴起。从这之后的一段时期内,自然语言处理主要采用基于规则的方法,这种方法依赖于语言学,它通过分析词法、语法等信息,总结这些信息之间的规则,从而达到翻译的效果。这种类似于专家系统的方法,泛化性差、不便于优化,最终进展缓慢,未能达到预期效果。
到了20世纪80、90年代,互联网飞速发展,计算机硬件也有了显著提升。同时,自然语言处理引入了统计机器学习算法,基于规则的方法逐渐被基于统计的方法所取代。在这一阶段,自然语言处理取得了实质性突破,并走向了实际应用。
而从2008年左右开始,随着深度学习神经网络在图像处理、语音识别等领域取得了显著的成果,它也开始被应用到自然语言处理领域。从最开始的词嵌入、word2vec,到RNN、GRU、LSTM等神经网络模型,再到最近的注意力机制、预训练语言模型等等。伴随着深度学习的加持,自然语言处理也迎来了突飞猛进。
3. 相关进展
接下来,我将介绍自然语言处理与深度学习结合后的相关进展。
3.1. word2vec
在自然语言中,词是最基本的单元。为了让计算机理解并处理自然语言,我们首先就要对词进行编码。由于自然语言中词的数量是有限的,那就可以对每个词指定一个唯一序号,比如:英文单词word的序号可以是1156。而为了方便计算,通常会将序号转换成统一的向量。简单做法是对单词序号进行one-hot编码,每个单词都对应一个长度为N(单词总数)的向量(一维数组),向量中只有该单词序号对应位置的元素值为1,其它都为0。
虽然使用one-hot编码构造词向量十分容易,但并不是一个较好的方法。主要原因是无法很好地表示词的语义,比如苹果和橘子是相似单词(都是水果),但one-hot向量就无法体现这种相似关系。
为了解决上述问题,Google的Mikolov等人于2013年发表了两篇与word2vec相关的原始论文[1][2]。word2vec将词表示成一个定长的向量,并通过上下文学习词的语义信息,使得这些向量能表达词特征、词之间关系等语义信息。word2vec包含两个模型:跳字模型(Skip-gram)[1] 和连续词袋模型(continuous bag of words,CBOW)[2],它们的作用分别是:通过某个中心词预测上下文、通过上下文预测某个中心词。比如,有一句话”I drink apple juice”,Skip-gram模型是用apple预测其它词,CBOW模型则是用其它词预测出apple。
3.1.1. CBOW
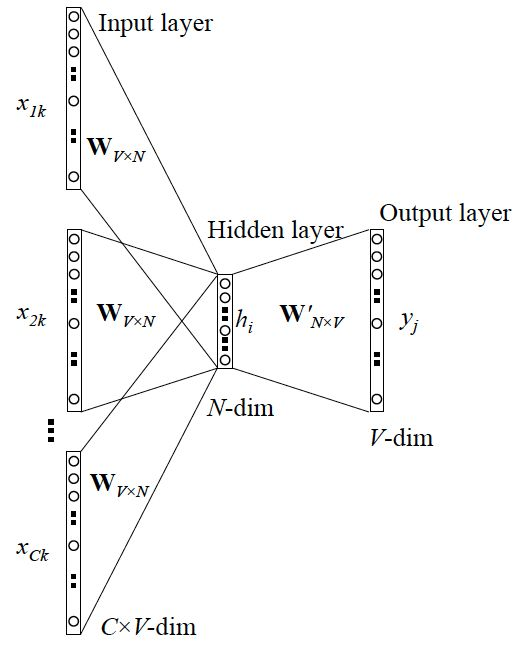
首先介绍CBOW模型,它是一个三层神经网络,通过上下文预测中心词。以某个训练数据”I drink apple juice”为例,可以把apple作为标签值先剔除,将”I drink juice”作为输入,apple作为待预测的中心词。
输入层: $x_i$ 是上下文中第i个单词的one-hot向量,长度为 $V$ 。比如在训练数据
I drink _ juice中,$x_2$就是词”drink”的one-hot向量。V是词库中词的总数,C是上下文中词的个数,k是训练集的大小。隐藏层:输入层$x_i$乘上$W_{V \times N}$求和即得到隐藏层,公式为$\sum_{i=1}^C x_i \times W_{V \times N}$。其中,$W_{V \times N}$是一个二维矩阵,V是词的总数,N代表着词的特征向量,长度可自定义。这个矩阵的每一行即可看作每个词对应的特征向量,而$x_i \times W_{V \times N}$就相当于取第i个词对应的特征向量。隐藏层没有激活函数,最后输出是一个$1 \times N$的向量。
输出层:输出层是中心词的预测值,一个$1 \times V$的向量。它由隐藏层输出乘上 $W_{N \times V}’$ ,并通过softmax激活函数得到,向量中每个位置的值相当于对应词的概率。中心词预测值会与实际值比较,并通过损失函数计算出损失值,再求出梯度值反向传播,最终更新 $W_{V \times N}$ 和 $W_{N \times V}’$ 的值。
3.1.2. Skip-gram
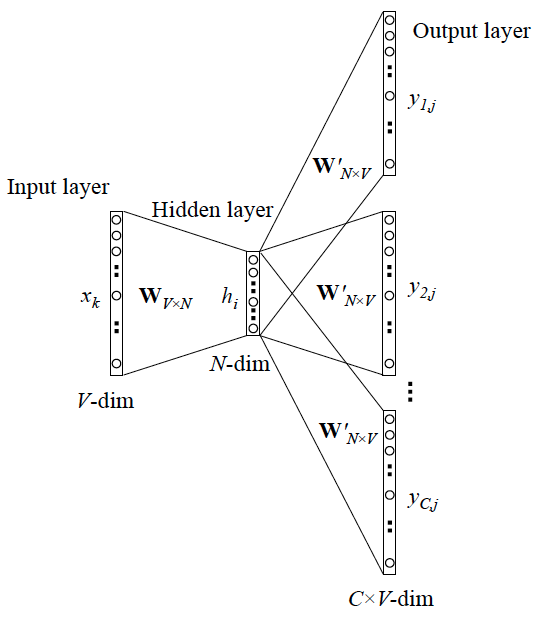
Skip-gram模型与CBOW类似,也是一个三层神经网络模型。不同在于,它是通过中心词预测上下文,即通过”apple”预测出”I drink juice”。接下来简单介绍Skip-gram模型中各层:
输入层:中心词的one-hot向量,$1 \times V$。
隐藏层:一个$1 \times N$ 的向量,输入层直接乘上$W_{V \times N}$即可得到。
输出层:由隐藏层乘上$W_{N \times V}’$并通过softmax激活函数得到,是一个$1 \times V$的向量。在这个向量中,与上下文相关的词所对应位置上的概率值较高。
两种模型训练结束后,会取 $W_{V \times N}$ 作为词向量矩阵,第i行就代表词库中第i个词的词向量。词向量可用来计算词之间的相似度(词向量点乘)。比如,输入I drink _ juice上下文,预测出中心词为apple、orange的概率可能都很高,原因就是在$W_{V \times N}$中apple和orange对应的词向量十分相似,即相似度高。词向量还可以用于机器翻译、命名实体识别、关系抽取等等。
其实这两种模型的原型在2003年就已出现[3],而Mikolov在13年的论文中主要是简化了模型,且提出了负采样与层序softmax方法,使得训练更加高效。
3.2. Transformer
词向量提出的同时,深度学习RNN框架也被应用到NLP中,并结合词向量取得了巨大成效。但是,RNN网络也存在一些问题,比如:难以并行化、难以建立长距离和层级化的依赖关系。而这些问题都在2017年发表的论文《Attention Is All You Need》[4]中得到有效解决。正是在这篇论文中,提出了Transformer模型。Transformer中抛弃了传统的复杂的CNN和RNN,整个网络结构完全由注意力机制组成。
3.2.1. Self-Attention
Transformer最核心的内容是自注意力机制(Self-Attention),它是注意力机制(Attention)的变体。注意力的作用是从大量信息中筛选出少量重要信息,并聚焦在这些信息上,比如:人在看一幅图像时,会重点关注较为吸引的部分,而忽略其它信息,这就是注意力的体现。但注意力机制会关注全局信息,即关注输入数据与输出数据以及中间产物的相关性。而自注意力机制则减少了对外部其它数据的关注,只关注输入数据本身,更擅长捕捉数据内部的相关性。
自注意力机制的算法过程如下:
将输入中one-hot编码的单词乘上word2vec中得出的词向量矩阵,得到单词的词向量。
将每个词的词向量分别乘上三个不同的矩阵,得到q、k、v三个向量。q是query,用来与k做匹配;k是key,代表着v的key;v是value,代表待提取信息的值。
依次将各个词的q与每个词的k点乘,再除于$\sqrt{d}$(d是q和k的维度)。比如,第1个单词对应的结果$a_{1,j} = q_1 \cdot k_j \div \sqrt{d}$,j从1到n,组成一个向量。
将上一步每个词的结果进行softmax。
最后,每个词的输出为$b_i = \sum_j(a_{i,j}v_i)$。
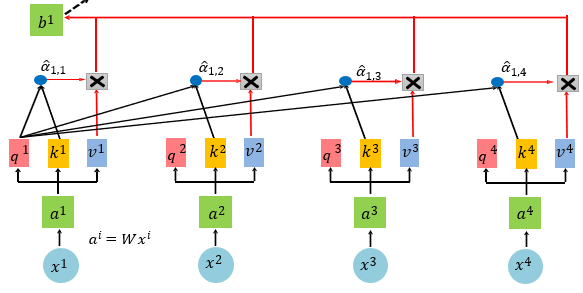
自注意力机制不仅建立了输入数据中词与词之间的关系,还能并行地高效地计算出每个词的输出。
3.2.2. Transformer
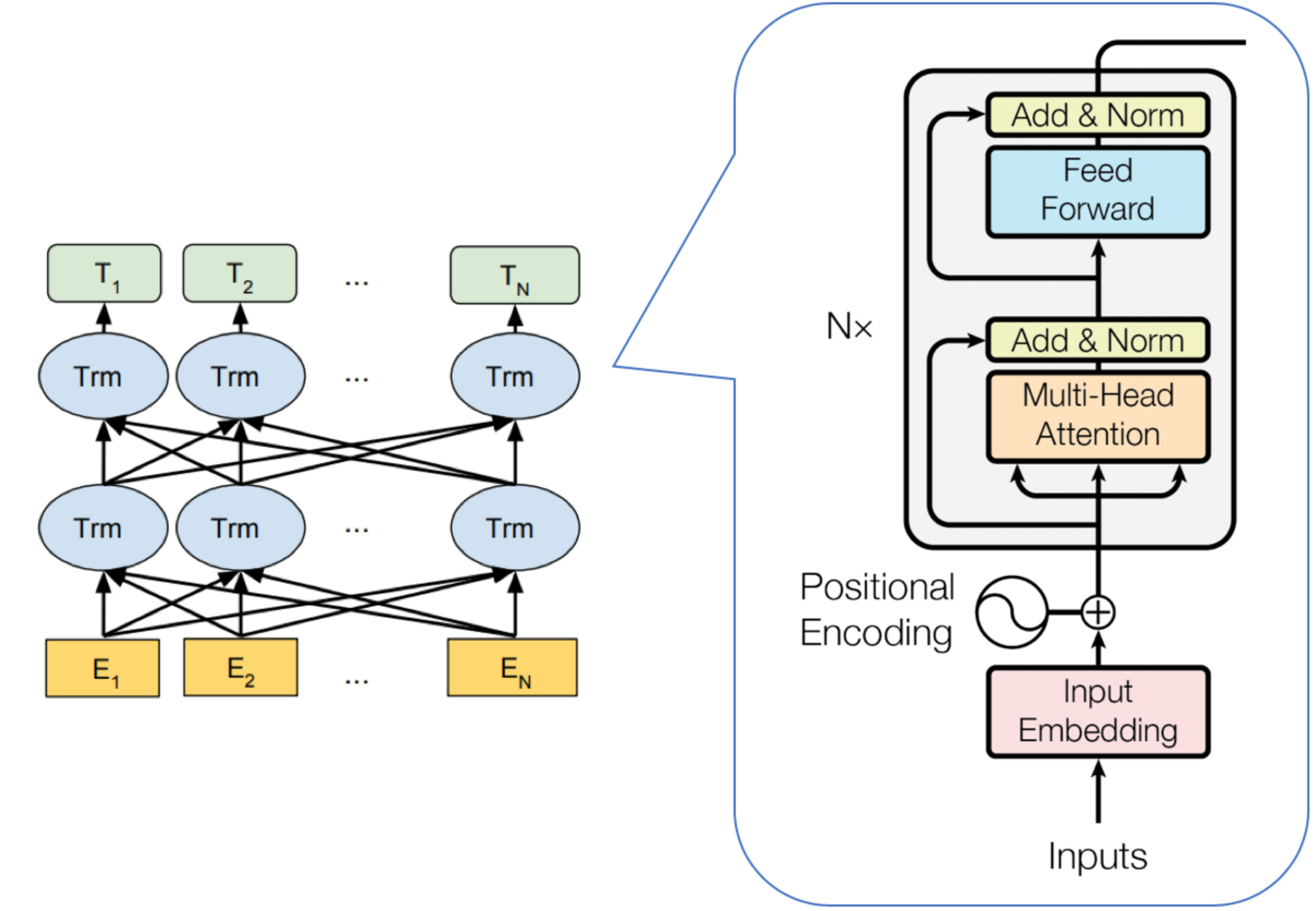
Transformer的总体架构如下:
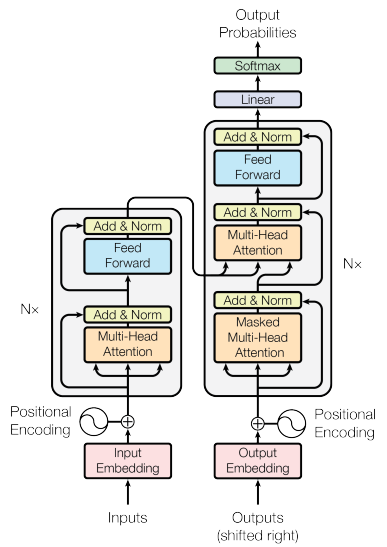
它分为两部分:编码器(Encoder)和解码器(Decoder)。
编码器的输入是词向量加上位置编码(表明这个词是在哪个位置),再通过多头自注意力操作(Multi-Head Attention)、全连接网络(Feed Forward)两部分得到输出。其中,多头自注意力就是输入的每个词对应多组q、k、v,每组之间互不影响,最终每个词产生多个输出b值,组成一个向量。编码器是transformer的核心,它通常会有多层,前一层的输出会作为下一层的输入,最后一层的输出会作为解码器的一部分输入。
解码器包含两个不同的多头自注意力操作(Masked Multi-Head Attention和Multi-Head Attention)、全连接网络(Feed Forward)三部分。解码器会运行多次,每次只输出一个单词,直到输出完整的目标文本。已输出的部分会组合起来,作为下一次解码器的输入。其中,Masked Multi-Head Attention是将输入中未得到的部分遮掩起来,再进行多头自注意力操作。比如原有5个输入,但某次只有2个输入,那么q1和q2只会与k1、k2相乘,。
3.3. 预训练模型
如果深度学习的应用,让NLP有了第一次飞跃。那预训练模型的出现,让NLP有了第二次的飞跃。预训练通过自监督学习(不需要标注)从大规模语料数据中学习出一个强大的语言模型,再通过微调迁移到具体任务,最终达成显著效果。
预训练模型的优势如下:
由于不需要标注数据,预训练模型可以从无限的文本中(比如互联网上大量的文本数据)学习通用的语法语义知识。
具有良好的复用性,通过微调可应用到具体任务,减少重复性劳动、节约资源。
预训练模型几乎在所有NLP任务中都取得显著成效。
预训练模型的关键技术有三个:
transformer。
自监督学习,它不同于监督学习,需要对目标数据进行标注,它是取输入中的一部分作为目标数据。常见的方法有:预测下一个词,输入一个句子的前一部分预测下一个词,预训练模型ELMo[5]和著名的GPT[6]等就是采用这种方法;遮盖输入,将句子中的某个词遮盖,通过模型来预测这个词,预训练模型Bert[7]则采用这种方法。
微调,是将预训练模型迁移到具体的任务上。具体方法是:在预训练模型上再叠加一层特定任务层,训练并进行调参时,可以固定预训练模型的参数,也可以调整预训练模型的参数,通常采用后者。由于目前的预训练模型都非常庞大,为了让预训练模型调参更加高效,又提出了Adaptor[8]。它插入在预训练模型中一起训练,但迁移调参时只需要Adaptor中的参数。
关于预训练模型的架构,以Bert为例:输入是词的one-hot编码向量,乘上词向量矩阵后,再经过多层transformer中的Encoder模块,最终得到输出。
4. 结束语
本文介绍了NLP领域的流行研究进展,其中transformer和预训练模型的出现,具有划时代的意义。但随着预训练模型越来越庞大,也将触及硬件瓶颈。另外,NLP在一些阅读理解、文本推理等任务上的表示,也差强人意。总而言之,NLP领域依旧存在着巨大的前景与挑战,仍然需要大家的长期努力。
5. 参考文献
[1]Mikolov, T., Sutskever, I., Chen, K., Corrado, G. S., & Dean, J. (2013). Distributed representations of words and phrases and their compositionality. In Advances in neural information processing systems (pp. 3111-3119).
[2]Mikolov, T., Chen, K., Corrado, G., & Dean, J. (2013). Efficient estimation of word representations in vector space. arXiv preprint arXiv:1301.3781.
[3]Yoshua Bengio, R´ejean Ducharme, Pascal Vincent, and Christian Janvin. A neural probabilistic language model. The Journal of Machine Learning Research, 3:1137–1155, 2003.
[4]Vaswani A, Shazeer N, Parmar N, et al. Attention is all you need[C]//Advances in neural information processing systems. 2017: 5998-6008.
[5]Peters M E, Neumann M, Iyyer M, et al. Deep contextualized word representations[J]. arXiv preprint arXiv:1802.05365, 2018.
[6]Radford A, Narasimhan K, Salimans T, et al. Improving language understanding by generative pre-training[J]. 2018.
[7]Devlin J, Chang M W, Lee K, et al. Bert: Pre-training of deep bidirectional transformers for language understanding[J]. arXiv preprint arXiv:1810.04805, 2018.
[8]Houlsby N, Giurgiu A, Jastrzebski S, et al. Parameter-efficient transfer learning for NLP[C]//International Conference on Machine Learning. PMLR, 2019: 2790-2799.